Should we adopt our regional Mother Tongue or choose English for learning? The Indian government is making the scientific ecosystem undergo a radical structural experiment. The government is aggressively pivoting towards teaching technical subjects, specifically Medicine (MBBS) and Engineering (B.Tech), in Hindi and other regional languages (emphasis on HIndi). This is not merely a political slogan but a rapidly implementing policy reality.
To ground this critique in fact, here are five specific news of this shift drawn from recent national reportage:
- MBBS in Hindi (Madhya Pradesh): In October 2022, Union Home Minister Amit Shah launched the country’s first Hindi-language MBBS course in Bhopal. The government released translated textbooks for Anatomy, Physiology, and Biochemistry, setting a precedent for other states (The Hindu, Oct 16, 2022).
- AICTE’s Regional Engineering Books: The All India Council for Technical Education (AICTE) has formally launched engineering textbooks in 12 regional languages, including Marathi, Bengali, Tamil, Telugu, and Kannada. This is part of a larger mandate to democratize technical education (Economic Times, April 7, 2025).
- Medical Education in Chhattisgarh: Following Madhya Pradesh, the Chhattisgarh government announced in September 2024 that it would introduce medical education in Hindi starting from the 2024-25 academic session, explicitly citing the Prime Minister’s vision (The Hindu, Sep 14, 2024).
- The “Medical Shabd Sindhu” Project: The Union Home Ministry has commissioned the creation of a massive “Medical Shabd Sindhu”, a standard English-to-Indian-language medical dictionary—to standardize terminology across 15 languages, facilitating future translations (The Hindu, Feb 13, 2026).
- Project ASMITA: The UGC and Ministry of Education launched Project ASMITA (Augmenting Study Materials in Indian Languages through Translation and Academic Writing) to produce 22,000 books in 22 languages within five years, aiming to create a self-sufficient vernacular academic ecosystem (The Hindu, July 17 2024).
The stated goal is to “decolonize” science and remove language barriers for rural students. However, to evaluate the success of this, we must look at the mechanics of the human brain and the mathematics of global information flow.
2. Neuroscience of learning complex problems in a second language
The strongest argument for the vernacular policy comes from cognitive science. Learning complex, novel concepts in a second language creates a specific type of neural friction known as the “Bilingual Disadvantage” in working memory.
A. Cognitive Load Theory: Intrinsic vs. Extraneous Load
The human brain’s working memory is finite. Cognitive Load Theory (CLT) postulates that when a student learns a new scientific concept (e.g., “Mitochondrial Oxidative Phosphorylation”), they face two types of load:
- Intrinsic Load: The inherent difficulty of the mathematical/biological concept itself (understanding proton gradients, ATP synthesis, etc.).
- Extraneous Load: The mental effort required to decode the medium of instruction.
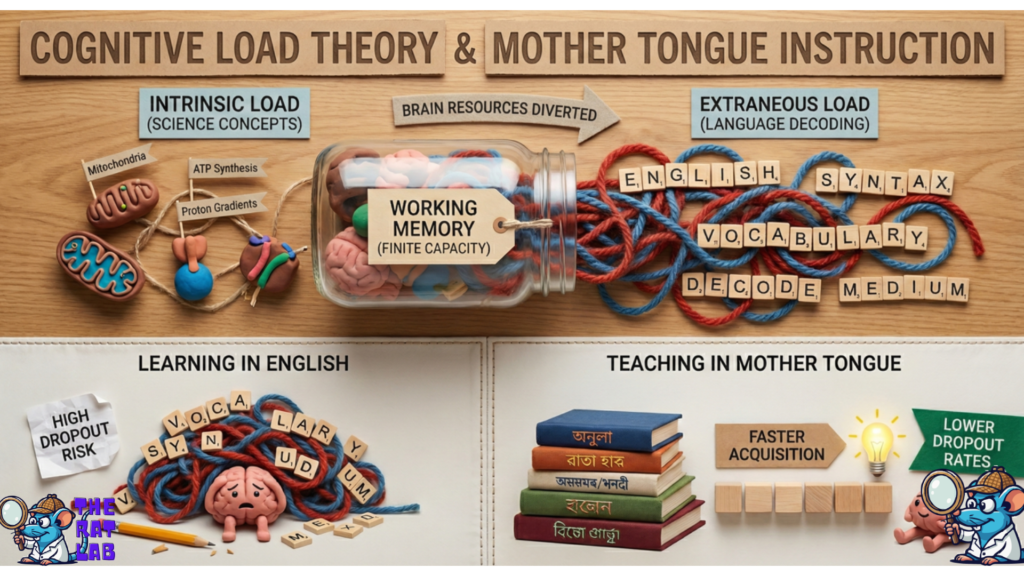
For a student whose mother tongue is Assameese/Hindi/Gujrati/Tamil/Bengali/Konkani etc. Indian languages, learning science in English imposes a massive Extraneous Load. Their brain must first decode the English syntax and vocabulary before it can even attempt to process the scientific logic. In neuroscientific terms, resources from the Prefrontal Cortex (PFC) responsible for executive function are diverted to linguistic decoding rather than conceptual schema formation.
By teaching in the mother tongue, the government aims to eliminate this extraneous load. The student’s working memory is freed to focus entirely on the Intrinsic Load of the science. Theoretically, this leads to faster acquisition of concepts and lower dropout rates among non-English speakers.
B. Semantic Encoding: “Grounding” vs. Rote Memorization
How does the brain store the concept of “Force” or “Energy”? In Neuropsychology, Semantic Encoding refers to the process of converting sensory input into meaning.
- Mother Tongue Advantage: Concepts in mother tongues are “embodied”, they are linked to sensory experiences, emotions, and early childhood memories. When a student hears the word ‘Bal’ or ‘Bol’ (Force), it triggers a deep semantic network formed since childhood.
- The Second Language Disconnect: When the same student hears “Force,” it is often stored as a lexical (just at the level of meaning, not understanding or feeling the concept of force) label, a word to be memorized for an exam, rather than a felt concept. This leads to “Shallow Encoding.”
The Science vs. Social Science:
However, a critical distinction exists between Science and Social Science. Social sciences (History, Sociology) are inherently cultural. Learning Indian History in our mother tongue adds nuance and depth because the concepts themselves are native to the language.
Hard sciences (Physics, Chemistry), however, are almost culturally invariant. An electron spins the same way in Japan as it does in India. While introductory concepts benefit from L1 grounding, advanced science relies on a global, standardized medium of understanding. If a student encodes “Entropy” only through a localized Indian language term that lacks the mathematical precision of the global term, they may suffer from Semantic Isolation, understanding the feeling of the concept but failing to grasp its precise mathematical definition used by the rest of the scientific world.
C. The “Translation Phase”: The Japan/China Misconception
A common defense of the Indian policy is: “Japan and China teach in their own languages, so why can’t we?”
This argument misses a crucial historical nuance regarding Lexical Creation (Dictionary Making) vs. Translation.
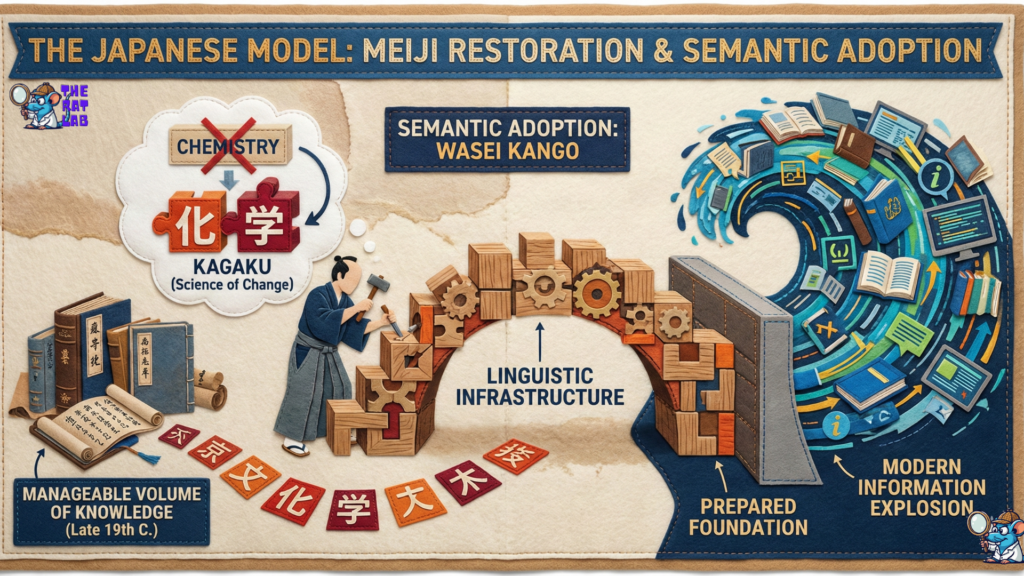
The Historical Divergence:
- The Japanese Model (Meiji Restoration): Japan did not just “translate” books; they engaged in Semantic Adoption. In the late 19th century, Japanese scholars coined thousands of new words (wasei kango) to create a native scientific lexicon. They didn’t just borrow the word “Chemistry”; they created Kagaku (Science of Change). Critically, they did this before the explosion of modern information. They built a linguistic infrastructure when the total volume of scientific knowledge was manageable.
- The Chinese Model: Similarly, China invested decades in “Nationalizing” terminology, creating characters that visually represented chemical elements.
The Modern Contrast:

India is attempting to do in the 2020s what Japan did in the 1880s. The volume of scientific literature today is exponentially higher. Japan and China are now actually reversing course at the higher levels. In modern Japanese and Chinese universities, there is immense pressure to publish in English. They have realized that while undergraduate education can be vernacular, research must be done in a globally accepted language, English.
India’s attempt to translate higher technical education (MBBS/B.Tech) risks creating a generation of students who have “Concept Clarity” but lack technical communication; they understand the science but cannot speak to the world about it or exchange ideas outside their language.
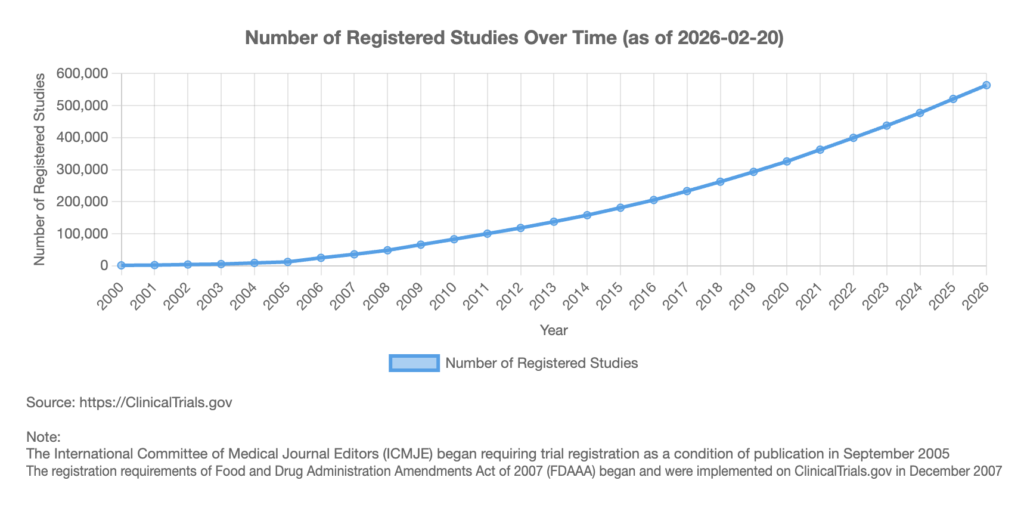
3. The Mathematics of Human Connectedness
If Neuroscience supports the local learner, Network Theory provides a devastating critique of the global scientist. We must treat the global scientific community as a Graph, where scientists are Nodes and citations/collaborations are Edges.
A. Scientific Network Topology: Centrality and Betweenness
Imagine the entire world of science not as a list of countries, but as a giant spiderweb. In mathematics, we call this a Network Graph. Every scientist or research paper is a “node” (a dot), and every time they talk to each other or cite each other’s work, they form a “link” (a line).
To understand why shifting languages matters, we have to look at how this web is built. In this web, not all dots are created equal. Some are massive junctions, and some are dead ends. We measure this using Centrality, which is just a fancy way of asking, “How important is this dot?” Specifically, we care about Betweenness Centrality. Think of this as the “Bridge Factor.” If you are a node with high Betweenness Centrality, you are like a busy international airport. To get from Point A to Point B, information has to fly through you.
Currently, global science has what we call a Scale-Free Topology. This is a specific type of network where a few “super-hubs” hold everything together (like how Google or Amazon dominate the internet). Right now, the English language is that super-hub. It is the dominant connector. If a biologist in Japan wants to use a discovery made in Brazil, the information almost always travels through English journals. English has the highest “Bridge Factor.”
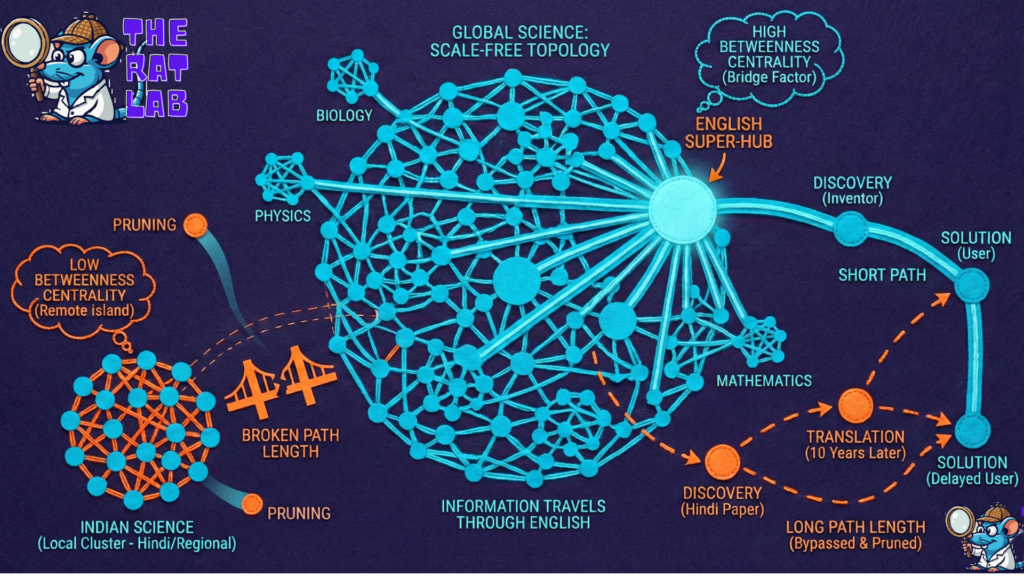
Now, look at the scenario where Indian scientists switch to creating or publishing primarily in Hindi or regional languages. In network theory terms, they form a Local Cluster. In social science, we might call this a “clique”, a tight-knit group that talks a lot to each other but rarely talks to outsiders. Their Betweenness Centrality, their power to act as a bridge, crashes. They are no longer the busy airport, they have become a remote island. The information flows within India just fine, but the bridge to the rest of the world is broken.
Why is this dangerous? It comes down to Path Length. Path Length is simply the number of steps an idea takes to get from the inventor to the user. If an Indian scientist writes a brilliant paper in Hindi, a lab at MIT won’t see it immediately. It might take 10 years for that paper to be translated, recognized, and then cited. We have effectively increased the “distance” between the discovery and the solution. This leads to a ruthless phenomenon in network evolution called Pruning. Networks are efficient; they like short paths. If a node (in this case, Indian science) has a low “Bridge Factor” and creates long, slow paths, the network eventually bypasses it. The node gets “pruned”, it stops receiving new energy and eventually becomes irrelevant to the growth of the whole system.
B. Information Latency: The Mathematics of “Translation Lag”
To understand this crisis, we must compare two types of motion: Exponential and Linear.
Science currently follows Exponential Growth. This means it doesn’t just move forward; it accelerates. The “Doubling Time” concept tells us that medical knowledge doubles roughly every 73 days. Imagine a snowball rolling down a steep hill, it gets bigger and faster every second.
Translation, however, is a Linear Process. It requires human effort (Using AI to translate the whole medical knowledge will be a risky idea because language to language mapping is a complex process), page by page, hour by hour. It is steady, like riding a bicycle. The problem arises when you try to chase the exponential snowball with the linear bicycle.
If a standard textbook takes two years to translate into Hindi, the math suggests a fatal flaw. By the time the Hindi/regional language version is printed, the science inside it has “doubled” or evolved ten times over. The book is technically obsolete before it reaches the student’s desk. This delay creates a phenomenon we call Structural Information Asymmetry.
Students reading in English access live, real-time feed of global discovery (like Nature journals or arXiv preprints). Students waiting for translations are accessing a saved, static version later. In slow fields, this might be okay. But in hyper-fast fields like Artificial Intelligence, a delayed version from 2024 is ancient history by 2026. The student isn’t just learning slowly, they are learning things that may already be proven wrong.
C. The “Silo Effect”: Evidence from Russia and Brazil
Is there proof that this hurts science? Yes. We can look at the “Silo Effect” in other non-English dominant scientific communities.
The Russian Case: Soviet science was formidable but notoriously siloed. Great discoveries (like the mechanisms of lasers or early computing) were often duplicated because Western scientists couldn’t read Russian papers, and vice versa. While Russia had a self-sustaining ecosystem, it suffered from a lack of ‘Cross-Pollination’. Post-1990s, as Russian scientists integrated into the English web, their citation metrics improved, but the historical lag left lasting scars on their institutional rankings.
The Latin American (Brazil) Data: Research into the “Citation Penalty” shows that papers published in Portuguese or Spanish (in journals like SciELO) have significantly lower Impact Factors and citation counts than papers from the same authors published in English.
A 2017 study in Scientometrics found a “penalty” for non-English papers: they are viewed by the network as “peripheral” regardless of quality.
By encouraging regional languages, India risks pushing its scientists into these low-impact peripheries. They will talk only to each other, creating a Closed Loop System that creates an illusion of activity but lacks global signal strength.
4. Synthesis
The debate is not a binary choice between “National Pride” and “Colonial Slavery.” It is an optimization problem between Cognitive Depth and Network Velocity.
The Balance Sheet
| Metric | Vernacular Model (Hindi/Regional) | English Model |
| Cognitive Load | Low (Optimal). Easier to grasp initial concepts. | High (Sub-optimal). Brain tax on decoding language. |
| Conceptual Depth | High. Concepts are felt and embodied. | Variable. Often leads to rote memorization. |
| Network Centrality | Very Low. High risk of isolation. | High. Direct access to the global “brain.” |
| Information Latency | High. Perpetual lag due to translation time. | Zero. Real-time access to discoveries. |
| Global Mobility | Restricted. Limited to national geography. | Unrestricted. Global workforce integration. |
The Critical Flaw in the Indian Approach
The Indian government’s mistake is not the promotion of Indian languages, but the timing and domain of its application. Attempting to translate Medical and Engineering education at the tertiary level is mathematically inefficient. The lexicon of these fields is already Anglicized globally. Trying to create a Hindi word for “Endoplasmic Reticulum” or “Eigenvector” in 2026 is a reverse-engineering effort that adds little value but creates massive friction.
The “Japan Defense” is Flawed: Japan succeeded because they modernized with their language in the 19th century. India is trying to modernize its language after the science has already been established in English. You cannot retro-fit a language to 300 years of scientific divergence in 5 years of policy shifts.
The Middle Path: The “Scandinavian Model”
A more scientifically robust approach, supported by both neuroscience and network theory, would be the Scandinavian Model (used by Sweden, Netherlands, Germany) which many of the states in India already have in place. The model says:
- Bilingual Competence: Retain the mother tongue for Primary and Secondary education to ensure deep cognitive grounding and semantic encoding. Teach the concepts of gravity, photosynthesis, and numbers in the Indian regional languages.
- Anglophone Switch: At the Tertiary Level (University), switch strictly to English. By age 18, the student has “Schematic Competence” (they understand the world). The brain is now plastic enough to map English terminology onto these existing vernacular schemas. This ensures they enter the global scientific graph as full nodes, capable of reading, writing, and collaborating in the Lingua Franca of science.
Conclusion:
The current policy of translating MBBS/B.Tech into Hindi/regional languages is a Neuroscientific Win but a Network Theory Disaster. It may produce doctors who understand the textbook better but cannot read the journal that updates the textbook. In the long run, “Connectedness” (Network) trumps “Ease” (Cognitive Load) in science, because science is a collective, cumulative enterprise.
India cannot afford to unplug from the global hive mind in search of linguistic comfort.
The evidence suggests that while we should Think in our mother tongue, we must Publish and Reference in English to remain relevant in the mathematical graph of human knowledge.



